Воно ще молоде, а вже яке хитре! ))
Ви помиітили, що про спілкування зі AI все менше шуткують? І ця відповідь не така вже лінійна.
До речі, мої учні помітили що Deepseek використовує багато смайлів…
Воно ще молоде, а вже яке хитре! ))
Ви помиітили, що про спілкування зі AI все менше шуткують? І ця відповідь не така вже лінійна.
До речі, мої учні помітили що Deepseek використовує багато смайлів…
Українська вишивка дуже різна. Елементи, малюнки, сенси.
Анітрохи не намагаючись спростити творчість, спробуємо написати двокольоровий алгоритм для вишивальної машини.
В коді вказано, де треба заправити нову нитку:
Код:
from turtle import *
def figure(line, step):
forward(line)
right(90)
forward(line + step)
right(90)
forward(line - step + 8)
right(90)
forward(line + step - 8)
while line < 200:
return figure(line + step // 4, step)
speed(0)
pensize(6)
c = ['green','red']
for x in range(2):
# визначаємо потрібний колір нитки
color(c[x % 2])
# заправляємо відповідну нитку
home()
right(45)
figure(16 - 8 * x, 16)
Хтось побачить тут творчий хаос, а хтось — сім рандомів. Хтось — простий шкільний приклад, а хтось — танцюючу тінь Джексона Поллока.
from random import randint
from turtle import *
speed(0)
for _ in range(randint(500,600)):
penup()
setpos(randint(-200,200), randint(-200,200))
pendown()
pensize(randint(5,45))
color('#%06x' % randint(0, 0xFFFFFF))
left(randint(2,20))
forward(randint(2,150))
Код:
from turtle import *
def paint(x):
for i in range(x, x + 1):
circle(70 + x, x)
left(40)
if x < 100:
return paint(x + 1)
speed(0)
pensize(2)
color('darkviolet')
paint(5)
Завдання для допитливих: яку мінімальну кількість рядків цього коду треба змінити, щоб ручка розписувалась так само, але не проти, а за годинниковою стрілкою?
Успіхів!
В 1996 році ізраїльська компанія Mirabilis запустила програму миттєвого обміну повідомленнями на ім’я ICQ. В наших краях цю неймовірну для свого часу штуку звали аською. Після кількох перекупів, останній власник виключив ICQ у 2024 році.
Але поки все працювало, у кожного користувача ICQ був свій ідентифікатор, так званий UIN (Universal Identification Number), що складався з 5-9 цифр. У кого був менший номер, той, іноді, дійсно вважав себе крутішим. У різних часів різні дефекти )
Для свого часу аська була неймовірна штука, бо зручне миттєве спілкування в XX столітті на кожному кроці не валялося.
А після преамбули ми розглянемо задачу на ім’я ICQ:
https://www.eolymp.com/uk/problems/443
Умова:
У деякій школі у кожного школяра є свій особистий номер ICQ. У школі поширена думка, що чим менше значення номера ICQ, тим більш «продвинутим» є школяр. Відомо список всіх школярів з номерами ICQ. Потрібно вивести список K самих «продвинутих» школярів.
Вхідні дані
У першому рядку міститься кількість учнів у школі N (1 ≤ N ≤ 100) і число K (1 ≤ K ≤ N). Далі йде N рядків, у кожному рядку міститься прізвище школяра (без пропусків, містить не більше 20 рядкових латинських букв) і через пропуск номер ICQ (1 ≤ ICQ ≤ 10^9). Номера ICQ і прізвища у школярів різні.
Вихідні дані
Вивести прізвища K самих «продвинутих» школярів у лексикографічному порядку (за алфавітом). Кожне прізвище виводиться в окремому рядку.
Приклади
Вхідні дані #1
1 1
d 1
Відповідь #1
d
Обмеження на час виконання: 0,5 секунди
Обмеження на використання пам'яті: 64 мегабайти
Нам буде зручно використати структурований список даних, елементом якого буде запис, в якому буде прізвище користувача та номер ICQ. Двовимірний список в Python нам може стати у пригоді. Для пояснення ми використаємо свій приклад. Наприклад, у нас буде 8 учнів, у кожного буде свій номер, а обирати ми будемо трьох самих «продвинутих», тобто тих, у кого найменші номери ICQ. Не забуваємо, що прізвища цих трьох нам буде треба відсортувати у лексикографічному порядку, тобто за алфавітом.
Наш приклад:
8 3
umkin 92654
dudkin 22654
mamkin 12754
papkin 82654
bubkin 92654
memkin 87054
titkin 222454
babaikina 12254
Після введення даних в кожному записі у нас першим параметром буде прізвище, а другим – номер ICQ. Гарний спосіб відсортувати дані за номером ICQ (перший параметр) надає Python за допомогою функції itemgetter модуля operator. Так просто:
data.sort(key = operator.itemgetter(1))
Після сортування списку ми можемо обрати лише потрібну кількість записів (k).
Дискусійним може бути питання, чи краще коригувати вже існуючий список:
data = data[:k]
мінус такого рішення: ми назавжди губимо повний список учнів і їх номерів ICQ (хоча для даної задачі, після сортування нам цей список більше не потрібний)
чи заводити новий список:
data_result = data[:k]
мінус такого рішення: для нового списку ми використовуємо пам’ять, яку могли б не використовувати.
Як правильно і як краще для цієї задачі – чудова тема для обговорення з вчителем, університетським викладачем або практикуючим розробником (це можуть бути дуже різні люди)
Отже, повний лістинг такого підходу:
import operator
data = []
n, k = map(int, input().split())
for _ in range(n):
name, icq = input().split()
data.append([name, int(icq)])
data.sort(key = operator.itemgetter(1))
data_ = data[:k]
data.sort(key = operator.itemgetter(0))
for x in range(k):
print(data[x][0])
Ось результат роботи програми:
babaikina
bubkin
dudkin
Але можна відсортувати наші дані без використання функції «itemgetter». Для цього можна використати лямбда-функцію. Наприклад, так:
data = []
n, k = map(int, input().split())
for _ in range(n):
name, icq = input().split()
data.append([name, int(icq)])
data.sort(key = lambda x: x[1])
data = data[:k]
data.sort(key = lambda x: x[0])
for x in range(k):
print(data[x][0])
Можете порівняти ці різні варіанти сортування. Обидва коди здають задачу на 100%.
Обирайте, пробуйте, успіхів!
Вітаю!
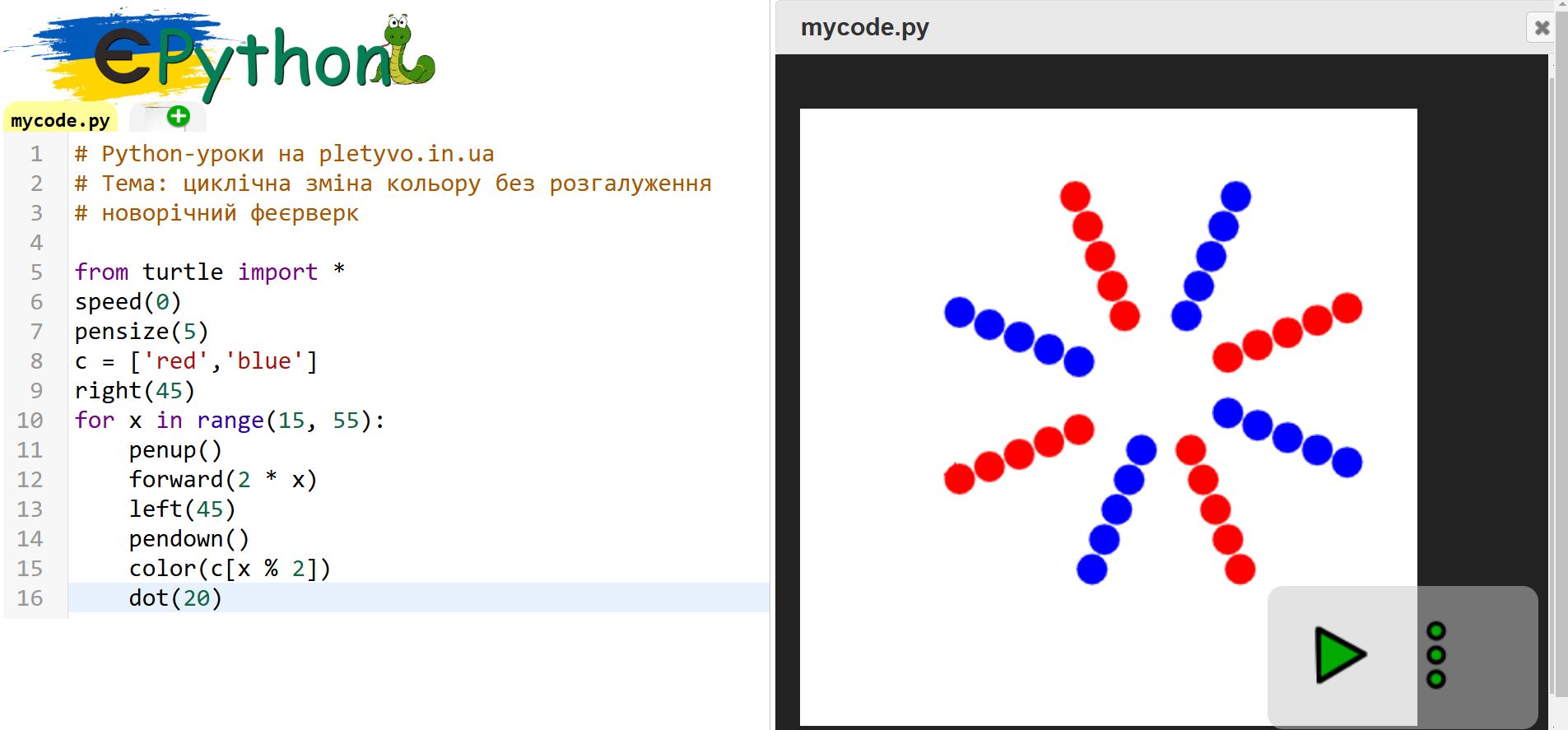
Для малювання феєрверку вирішив циклічно змінювати кольори: червоний-синій-червоний-синій... Звичайно, можна змінювати актуальний колір за допомогою розгалуження. Але у нас в циклі є змінна циклу (x), яка в даному прикладі змінюється як парна-непарна-парна-непарна... Тому для задачі зміни кольору не потрібно витрачати час на розгалуження. В прикладі можна переглянути один з можливих варіантів.
from turtle import *
speed(0)
pensize(5)
c = ['red','blue']
right(45)
for x in range(15, 55):
penup()
forward(2 * x)
left(45)
pendown()
color(c[x % 2])
dot(20)
Темою випуску є чудова задача, представлена на ІІІ етапі Всеукраїнської олімпіади з інформатики в Житомирській області 26 січня 2024 р.
Балансуючі елементи:
https://basecamp.eolymp.com/uk/problems/11658
Умова:
Задано послідовність з N елементів, які є цілими числами. Назвемо «балансуючим елементом» такий, що сума всіх елементів перед ним дорівнює сумі елементів після нього. При цьому перший та останній елементи послідовності не можуть бути «балансуючими».
Знайдіть кількість «балансуючих елементів» у заданій послідовності.
Вхідні дані
У першому рядку записане ціле число N. У другому рядку записано N цілих чисел, розділених пробілом. Всі числа не перевищують за модулем 100000.
Вихідні дані
Виведіть одне число – кількість «балансуючих елементів».
Приклади
Вхідні дані #1
3
1 2 1
Відповідь #1
1
Звичайно, ми можемо розмістити елементи у список, що дозволить зручно їх опрацьовувати.
Один з очевидних підходів полягає у виборі потенційно балансуючого елемента, починаючи від другого і до передостаннього і розрахунку суми елементів зліва від нього і справа від нього. Якщо ці дві суми співпадають, то елемент є «балансуючим» і ми збільшуємо лічильник кількості «балансуючих» елементів.
Звичайно, це гарно: if sum(s[:x]) == sum(s[x + 1:]), але головна проблема такого підходу полягає в тому, що нам при аналізі кожного потенційно балансуючого елемента необхідно двічі виконати операцію підрахунку суми елементів, зліва і справа. А це займає багато часу. І тому код на основі такого алгоритму не проходить по часу всі тести. На Python точно не проходить. Чудово, що автори задачі так підібрали тести, що це мотивує шукати більш оптимальні розв'язки.
Наступний алгоритм, більш оптимальний, полягає в тому, що при аналізі ми можемо рахувати суму елементів лише з одного боку. На початку програми ми можемо один раз підрахувати суму всіх елементів. А далі обирати циклом потенційного кандидата на роль балансуючого елемента і рахувати суму елементів, наприклад, лише зліва від нього. Тоді, якщо елемент, що розглядається, дійсно балансуючий, то загальна сума всіх елементів, мінус значення самого елементу, повинні дорівнювати подвійній сумі зліва. Це і буде означати, що сума зліва дорівнює сумі справа. Але і тут у нас при аналізі кожного елементу буде потрібно рахувати суму всіх елементів зліва від нього. А це також не швидко. Автори задачі знову чудово підібрали тести і Python-код на основі даного алгоритму не розв’язує повністю задачу за визначений час.
Розглянемо ще більш оптимальний алгоритм. Ми взагалі не будемо при аналізі кожного елементу рахувати суму зліва. Давайте визначимо якусь змінну, наприклад «left», в якій будемо накопичувати суму елементів зліва від того, що наразі аналізується. Коли ми перейдемо до наступного елемента, ми просто додамо до значення змінної «left» значення одного єдиного елемента, того що лівіше. Це буде значно швидше. Переглянувши всі елементи з другого до передостаннього, накопичуючи значення змінної «left» і маючи один раз пораховану на початку програми суму всіх елементів, ми за визначений час розв’яжемо задачу на 100%.
Кода не буде, якщо у вас не виходить це розписати, питайте.
Успіхів!